背景
初步的测试一下openGauss与PostgreSQL数据库的全表扫描的的性能对比。
操作系统:Oracle Linux 7.8
机器环境:Dell R630,128GB内存,CPU情况如下:
Architecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 72On-line CPU(s) list: 0-71Thread(s) per core: 2Core(s) per socket: 18Socket(s): 2NUMA node(s): 2Vendor ID: GenuineIntelCPU family: 6Model: 79Model name: Intel(R) Xeon(R) CPU E5-2686 v4 @ 2.30GHzStepping: 1CPU MHz: 2839.654CPU max MHz: 3000.0000CPU min MHz: 1200.0000BogoMIPS: 4600.06Virtualization: VT-xL1d cache: 32KL1i cache: 32KL2 cache: 256KL3 cache: 46080KNUMA node0 CPU(s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42,44,46,48,50,52,54,56,58,60,62,64,66,68,70NUMA node1 CPU(s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43,45,47,49,51,53,55,57,59,61,63,65,67,69,71Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt_a rdseed adx smap intel_pt xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts md_clear flush_l1d
测试场景
建测试表:
create table test01(id int, n int, t text);
生成测试数据:
insert into test01 select seq, seq / 100000, md5(seq::text) from generate_series(1, 1000000000) as seq;
总共生成了10亿条数据,表的大小为71GB。多次读表,让其数据都换成到内存中,不产生IO。
openGauss5.0的测试结果
如下图所示:
从上面可以看出扫描71G大小的10亿条记录的表花费了122秒。
PostgreSQL 13.6的测试结果

从上面可以看到时间为72秒。
另PostgreSQL支持并行查询,如果开启并行,就更块了:
结论
PostgreSQL 13的全表扫描性能是openGauss的1.69倍。
后记
有爱好者让看看如果使用向量化引擎,性能是否提升:
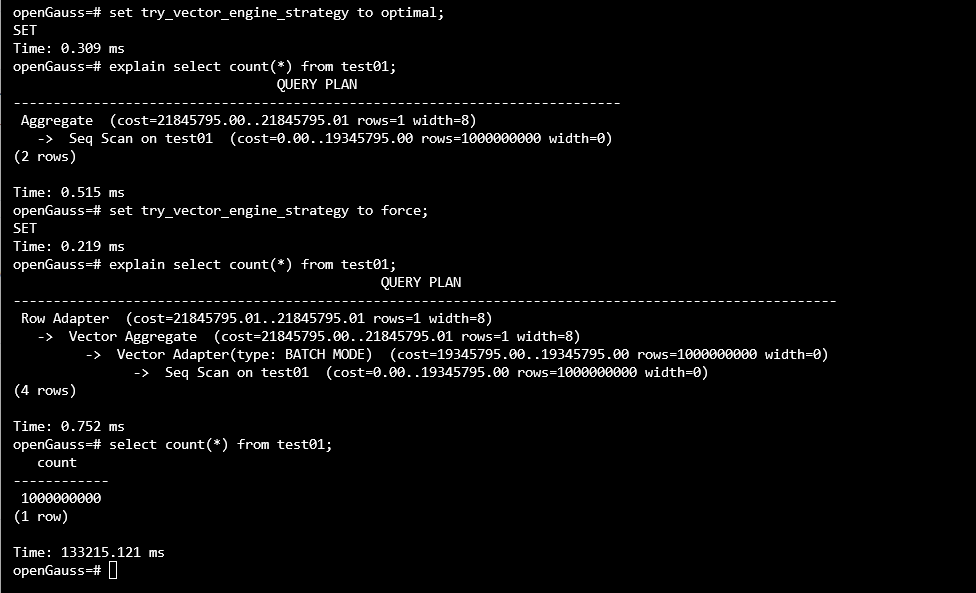
更慢了一些。
本站文章,未经作者同意,请勿转载,如需转载,请邮件customer@csudata.com.
0 评论
添加一条新评论
用户登录

- 1PostgreSQL10~13版本以来的新特性史上最全总结 - 31 阅读
- 2PostgreSQL新手指引 - 27 阅读
- 3 openGauss数据与PostgreSQL的差异之全局临时表 - 21 阅读
- 4声明:CVE-2019-9193 不是安全漏洞 - 21 阅读
- 5查看PostgreSQL数据库进程占用内存的正确姿势 - 19 阅读
- 6关于PostgreSQL的绑定变量窥视的问题详解 - 18 阅读
- 7在macos电脑上jdbc无法连接数据库而psql可以连接数据库的诡异问题的解决 - 17 阅读
- 8关于PostgreSQL的分区表的历史及分区裁剪参数enable_partition_pruning与constraint_exclusion的区别 - 14 阅读
- 9PostgresSQL inet与cidr类型 - 14 阅读
- 10openGauss5.0与PostgreSQL数据库的全表扫描的性能对比 - 13 阅读
- 1PostgreSQL新手指引 - 210 阅读
- 2PostgreSQL新手指引 - 210 阅读
- 3PostgreSQL新手指引 - 210 阅读
- 4PostgreSQL10~13版本以来的新特性史上最全总结 - 139 阅读
- 5PostgreSQL10~13版本以来的新特性史上最全总结 - 139 阅读
- 6PostgreSQL10~13版本以来的新特性史上最全总结 - 139 阅读
- 7PostgreSQL与MySQL 分析对比 - 122 阅读
- 8PostgreSQL与MySQL 分析对比 - 122 阅读
- 9PostgreSQL与MySQL 分析对比 - 122 阅读
- 10PostgreSQL14新特性:索引方面的增强 - 116 阅读
- 1PostgreSQL新手指引 - 1080 阅读
- 2PostgreSQL新手指引 - 1080 阅读
- 3PostgreSQL新手指引 - 1080 阅读
- 4PostgreSQL10~13版本以来的新特性史上最全总结 - 729 阅读
- 5PostgreSQL10~13版本以来的新特性史上最全总结 - 729 阅读
- 6PostgreSQL10~13版本以来的新特性史上最全总结 - 729 阅读
- 7PostgreSQL14新特性:索引方面的增强 - 663 阅读
- 8PostgreSQL14新特性:索引方面的增强 - 663 阅读
- 9PostgreSQL14新特性:索引方面的增强 - 663 阅读
- 10查看PostgreSQL数据库进程占用内存的正确姿势 - 635 阅读